
Generative AI for all: Video Diffusion models
Published:
Introduction
Have you ever played with a flipbook? You draw a picture on each page, and when you flip the pages really fast, the pictures move like a cartoon. Fun, right?

Now, let’s make it magical! Imagine a magic machine that doesn’t just draw one picture for you - it creates a whole flip book! And not just any flip book… this one makes the pictures move smoothly, like real life. Why is that important? Because a video is nothing more than a bunch of pictures shown one after another. If the pictures change too much from one page to the next, the motion looks jumpy and weird. But if each picture changes just a little, the motion feels natural and smooth.
That’s what video diffusion models do! They work super hard to make sure every picture in the flip book connects nicely to the next one, so your story flows like magic.
On learning of magical machines
Let us continue from our classroom story. The teacher comes back to class and says,
“Guess what, kids? Today, we’re not just drawing one picture - we’re making a whole magic flip book. But, first let us see some before you get to make your own!”
She brings out some flip books filled with clear and neat pictures in a sequence. But then she remembers her last fun experiment and decides to spice things up! Instead of showing the perfect flip books, she grabs a bag of magic dust and sprinkles it all over the pages, covering the pictures in funny little dots.


The students giggle and look closely at the different flip books, trying to spot the objects of interest hidden in the noisy, dusty pictures. Like previously, the teacher then divided the class into two teams and announced that each team would learn about the pictures in a different way.
Team CNN: The Keyhole Explorers
The teacher gathered the students around and revealed four image frames of Bluey running joyfully along the beach where each frame captured a different moment.
To make the learning process magical, the teacher appointed a team lead and said:
“The team lead’s special job will be to decide the order in which the students would stand. But here’s the twist: each time, the order will be completely random!”
The adventure began.
- First round: The team lead called out a random order. Each student, clutching their magic cardboard keyhole, stepped up to peek at a tiny part of one frame. Maybe one saw Bluey’s ear, another the sparkling sand, another a patch of sky and verified their understanding from the teacher. Their task was to study the fine details of their assigned part, memorizing every curve and color.
- Next round: The team lead shuffled the order again. Now, each student peered through their keyhole at a different frame and a different part. The details changed: sometimes it was Bluey’s tail, sometimes a seashell, sometimes the foamy edge of a wave. Each student compared what they saw with what they’d learned before, noticing how the same object could look different in another frame.
- And Again: The process repeated, with the team lead inventing new orders each time. Students swapped frames and parts, learning about every detail from every possible perspective. The classroom buzzed with excitement as discoveries piled up.
- Exhausting All Orders: The team lead kept going until every possible order had been tried. By the end, each student had seen every part of every frame, but always through their tiny keyhole - never the whole picture at once.
The students became experts at recognizing tiny details, no matter where they appeared or in which frame. They were like detectives, piecing together the story from small clues. Even though they never saw the whole image at once, their combined knowledge helped them understand the entire sequence of Bluey’s run.
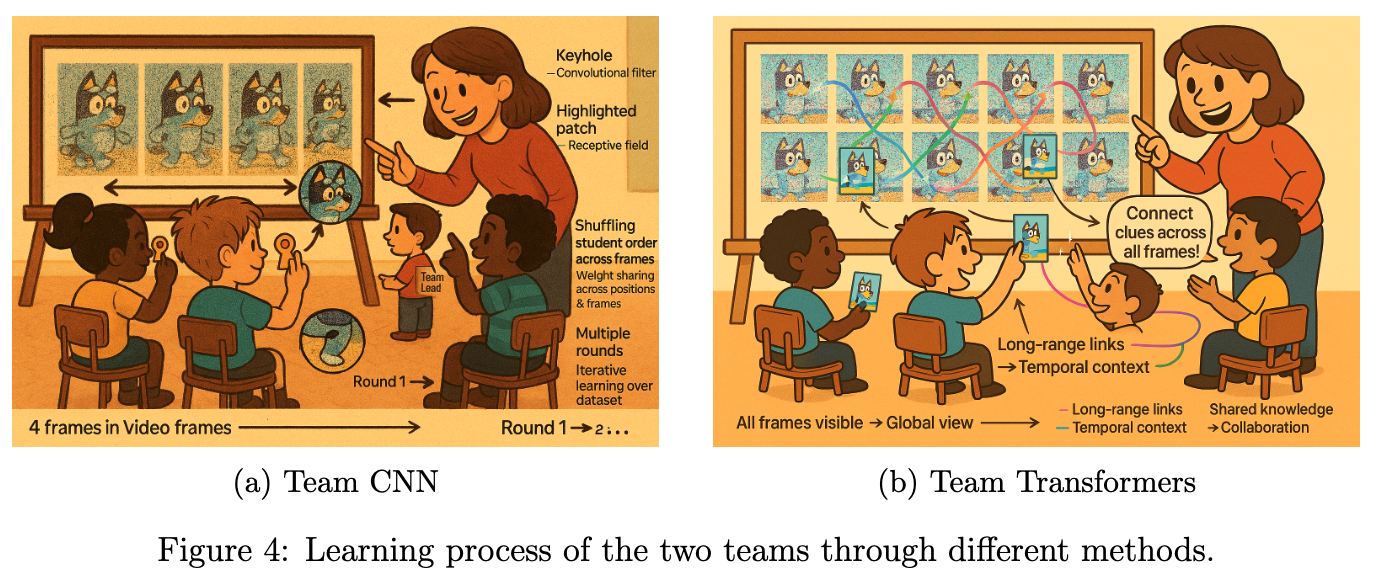
Team Transformers: The Puzzle Patchers
While Team CNN explored the flip book frame by frame, for Team Transformers the teacher had a different approach. She said:
“You will not have any team lead. But I want all of you to talk to each other to figure out the details.”
Instead of looking at one image at a time, the teacher gave them a giant board filled with patches from all the images in the video flip book - like a huge jigsaw puzzle scattered across time. Each student received several puzzle patches, but these patches weren’t just from one frame - they came from different moments in the story. Some showed Bluey’s tail in the first frame, others the waves in the middle, and some the sky in the last frame. The challenge was to figure out how all these pieces fit together, not just within a single image, but across the entire sequence. The teacher encouraged the students to talk, swap patches, and look for patterns that connected the beginning, middle, and end of the video.
“Notice how Bluey’s tail moves from left to right across the frames,” she said. “Or how the color of the sky changes as the story unfolds. Your job is to connect these clues and build the whole story in your minds.”
As the students worked together, they realized something magical: by seeing patches from all the images at once, they could understand how every part of the video was related. They spotted patterns that stretched across time - how the sand sparkled in every frame, how Bluey’s run became faster, and how the waves rolled in and out.
Unlike keyhole explorers, puzzle patchers did not just learn about one image at a time. They learned about the whole video - how every patch, every detail, and every moment fit together to create a smooth, flowing story. the teacher continued the experiment with the other flip books she had.
The magic movie challenge
The teacher clapped her hands and wrote today’s challenge on the board, in big, shimmering chalk: Bluey walking on the moon after coming out of the spaceship.
“Class,” she said, “this is our story prompt. Every frame you draw should follow this idea. Bluey steps out, touches moon dust, takes a few bouncy steps, and the spaceship glows behind. We want the whole flipbook to feel like one smooth scene.”
She placed blank pages on every desk and, as before, sprinkled a thin fog of magic dust over them. “We’ll clear the dust little by little,” she smiled. “Each pass makes the pictures cleaner. After every pass I’ll check how well your drawings match the story and give you feedback so you can improve.”
“Small steps, steady changes,” she repeated. “Let the moon feel light beneath Bluey’s feet.”
Team CNN: The Keyhole Explorers - The Team Lead stood up and said, “Let’s draw our story one frame at a time! I’ll tell you who goes first.”
- First round: The first student drew Bluey stepping out of the spaceship. The next student drew Bluey taking a small step onto the moon. The third added Bluey’s paw touching the moon dust. Each student focused on their own frame, making sure to change just a little bit from the last one—like flipping through a cartoon book.
- Teacher’s feedback: The teacher looked at all the pictures and said, “Nice job! But Bluey’s steps are too big, and the stars moved. Next time, make smaller changes and keep the background the same.”
- Next rounds: The Team Lead switched up who drew which frame. Some students worked on footprints, others on the spaceship. With each round, the drawings got smoother and more connected. The team learned to copy a little from the frame before and make tiny changes, so the story looked just right.
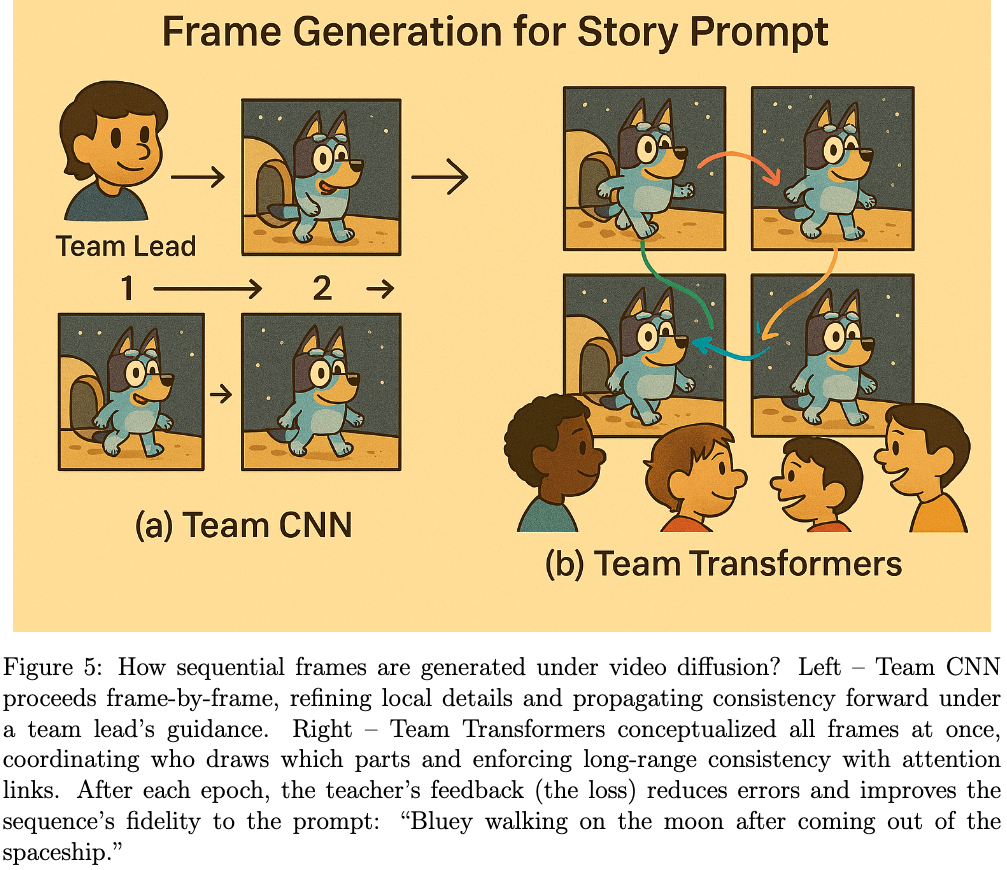
Team Transformers: The Puzzle Patchers - The teacher smiled and said, “You don’t need a team lead. Instead, talk to each other and plan together!”
- First round: The students gathered around a big board showing all the frames at once. They chatted and decided who would draw which part of the story. “I’ll draw Bluey stepping out of the spaceship!” “I’ll add the moon dust and footprints!” “I’ll make sure the stars and spaceship look the same in every frame!” They worked together, sharing ideas and making sure every frame fit perfectly with the others - like putting together a giant puzzle.
- Teacher’s feedback: The teacher looked at their drawings and said, “Great teamwork! But Bluey’s footprints are too close together, and the spaceship glow changes. Next time, keep things steady and spread out the footprints.”
- Next rounds: The students talked even more, fixing their pictures and helping each other. They made sure Bluey’s walk looked smooth and the moon scene stayed the same. By the end, their flip book told the story just right—everyone’s drawings matched up, and Bluey’s adventure flowed from start to finish!
In the end, both teams made something really beautiful out of the dusty mess, and the pictures looked almost perfect! Just like you can see in Figure 6, Team Transformer did a great job showing exactly what the teacher asked for - Bluey walking on the moon after coming out of the spaceship

The Magic Machine Analogy
In the world of modern AI, our story mirrors the inner workings of a magic machine, a generative model that can turn words into moving pictures. Here is how the pieces fit, which a more experienced reader might find analogous in the following way:
- Learning Backbone → The Builders: The machine needs strong builders to understand patterns. These are like the CNN team (masters of local details) and the Transformer team (experts in global context). Together, they form the backbone that learns how images are structured. In contrast to the diffusion models in this magical machine, there’s a special helper for the CNN team: the class monitor, a wise and watchful figure who ensures every student’s work fits together. Whenever a student forgets a detail from earlier, the monitor whispers a reminder, helping everyone remember what came before and making sure the story stays consistent from start to finish. This is analogous to skip connection mechanism. For the transformer team they can talk with each other to figure out the flow.
- Language Alignment → The Teacher’s Instructions: Like the teacher gave clear directions—“Bluey walking on the moon after coming out of the spaceship”, the magic machine uses language-image alignment (like CLIP) to connect what we say with what it draws.
- Generative Power → The Creative Drawing: When the machine starts creating, it’s like the students drawing the scene from the teacher’s words. This is the essence of Generative AI - turning text into sequential pictures.
- Mode Collapse → Everyone Drawing the Same Thing: To avoid everyone’s drawing looking similar, the teacher adds the dust concept. That’s like mode collapse, where the model produces similar outputs instead of diverse ones, which can be avoided by adding random noise in the learning process.
Conclusion
In the end, the classroom experiment showed something amazing: making pictures and movies isn’t just about copying what you see - it’s about building something new from a messy start! The team CNN became experts at tiny things, the Team transformers learned how everything fits together, and the teacher’s instructions helped everyone turn words into pictures. The students learned to construct the picture from scratch, guided only by the story. This mirrors how modern generative models work:
- Backbones like CNNs and Transformers provide the foundation.
- Language alignment (such as CLIP) connects words to images.
- Diffusion strategies start from noise and iteratively de-noise, ensuring diversity and creativity while staying true to the prompt.
- A global context for frame alignment is adopted in a smart way.
Just like the students’ final flip books, these magical models turn random chaos into wonderful movies—one step at a time, guided by the story.
“From dust to detail, video diffusion models create magic, turning words into moving pictures!”
Glossary
| Term | Meaning |
|---|---|
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| CLIP | Contrastive Language Image Pretraining |
| Diffusion | The process of adding and removal noise to a picture |
| Factorized Diffusion | The process of diffusion in steps |
| Language Alignment | Turn text into pictures |
| Mode Collapse | When a computer generates the same picture over and over |
| Transformers | Neural network architecture for context understanding |